


Automated Design of Tiny Machine Learning Models: A Practical Guide (Part 2)
In the first part of this article, the authors introduced the trends for the IoT industry and reviewed the key challenges for TinyML adoption which are faced by the embedded developers' community. They also described the traditional end-to-end development methodology for TinyML algorithm design and its drawbacks. In continuation, the authors will offer a novel approach to NN development supported by practical cases.
Practitioners look for ways to improve the existing methodology, so end-users can experience creating TinyML solutions that are easily deployable on the smallest MCUs and sensors, which are significantly constrained from a compute and power perspective. This article will also illustrate the procedure with examples of how practitioners can create optimal solutions in terms of the model footprint and inference time. Lastly, it will provide an example of a different approach using a typical Neural Network industry Framework called Neuton.AI. It automates neuron-by-neuron network structure growth and empowers users to build models of minimal size without losing accuracy.
Six technological innovations can describe the uniqueness of this approach:
- The selective approach to connected features helps to establish only necessary neuron connections while creating a model, not allowing the structure to grow randomly.
- A global optimization algorithm enables the platform not to base its computation on the backward propagation of errors and stochastic gradient descent. In addition, it allows the successful creation of compact models that minimize the likelihood of hitting local minima.
- The principle of neuron-by-neuron structure growth ensures learning from general features to the most specific ones and selecting almost any model precision and size required to solve the problem.
- There is no random manual search for Neural Network parameters such as the number of layers and neurons in a layer, type of activation function, batch size, learning rate, etc.
- Constant cross-validation helps to increase the generalizing capabilities of the model.
- Instances of a reduced operator set help to create many variants with minimal types of diversified operators that are easier to port on the embedded executor.
Worth noticing that all these aspects make integer post-training quantization, pruning, sparsity, and distillation unnecessary and eliminate the need for model compression after its creation.
The automated platform allows users to build extremely compact models without losing accuracy and embed them into any microcontroller, even with 8-bit or 16-bit precision.
From a practitioner's perspective, the process of ANN creation includes the following steps:
- Preparing a dataset in CSV format and selecting the columns that should be trained for prediction;
- Initiate training that is performed automatically without practitioner intervention;
- Download and deploy the model on an embedded target using an interoperable format (such as .h5 or .onnx).
Deployment Optimization for STM32 MCUs
To convert the model to an optimized code for an STM32 microcontroller to execute, the practitioner typically uses STM32CUBEMX. It is a graphical tool that allows a very easy configuration of STM32 microcontrollers and microprocessors, as well as the generation of the corresponding initialization C code for the Arm® Cortex®-M core or a partial Linux® Device Tree for Arm® Cortex®-A core through a step-by-step process.
The first step consists of selecting either an STM32 microcontroller, microprocessor, or a development platform that matches the required peripherals or an example running on a specific development platform.
For microcontrollers and microprocessor Arm® Cortex®-M, the second step consists in configuring each required embedded software thanks to a pinout-conflict solver, a clock-tree setting helper, a power-consumption calculator, and a utility that configures the peripherals and the middleware stacks. The default software and middleware stacks can be extended thanks to enhanced STM32Cube Expansion Packages. Eventually, the user launches the generation that matches the selected configuration choices. This step provides the initialization C code for the Arm® Cortex®-M, ready to be used within several development environments, or a partial Linux® Device Tree for the Arm® Cortex®-A. Finally, STM32CubeMX is delivered within STM32Cube.
X-CUBE-AI is a STM32Cube Expansion Package extending STM32CubeMX capabilities with automatic conversion of pre-trained Artificial Intelligence algorithms, including Neural Network and classical Machine Learning models, and integration of generated optimized library into the user's project. In addition, Keras Customized Layers' support lets developers unleash creativity and create differentiation into network topologies. For example, the latest version can be used to deploy pre-trained Deep Quantized Neural Network (DQNN) models designed and trained with the QKeras and Larq libraries. The X-CUBE-AI Expansion Package also offers several ways to validate Artificial Intelligence algorithms on desktop PCs and STM32 and measure performance on STM32 devices without user-handmade ad hoc C code.
Figure 1
Case Studies Illustrating the Effectiveness of the Novel Approach
The approach described in this article demonstrates how the process of creating TinyML solutions can be optimized due to two steps used in sequence:
- automatic creation of neural networks using the Neuton Neural Network Framework
- subsequent optimization of the resulting model code for the STM32 MCU using the X-CUBE-AI solution
To illustrate the effectiveness of this approach, the results of three well-known use cases are presented: Sussex-Huawei Locomotion (SHL)[1], PAMAP2[2], and SisFall[3]. The task of each classification model was to identify the class to which the action belongs based on signal data. Within each experiment, model validation has been performed on an out-of-sample test set. Detailed descriptions of each case are given below.
The results of models built with the Neuton Neural Network Framework and six alternative algorithms were compared during these experiments. Given comparable accuracies, models built using Neuton's Neural Network Framework can be hundreds of times smaller while not requiring any compression techniques before embedding in the respective MCU. It is also important to emphasize that using Neuton's Neural Network Framework, models were built automatically in one single iteration.
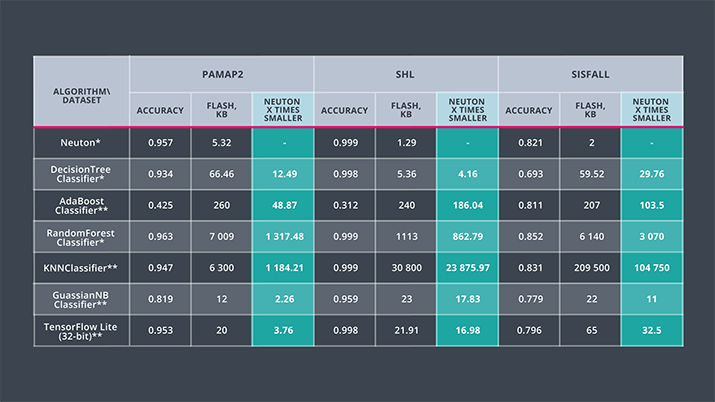
Figure 2: Summary metrics on the tested datasets (*: measured by X-CUBE-AI v. 7.1.0; **ONNX model file size. Not measured by X-CUBE-AI. All models have 32-bit single float precision).
The mentioned datasets and model creation outlines are available in a publicly accessible GitHub repository (https://github.com/NeutonTinyML/X-CUBE-AI), while their brief descriptions follow.
Sussex-Huawei Locomotion (SHL): this is a versatile annotated dataset of modes of locomotion and transportation of mobile users. It was recorded for 7 months in 2017 by 3 participants engaged in 8 different modes of transportation in a real-life setting in the United Kingdom. The goal is to classify one of 8 different activities: Still, Walk, Run, Bike, Car, Bus, Train, or Subway.
The window with 64 sequential records was selected to represent the signal class.
Model training and validation were performed on the subset of accelerometer, gyroscope, and linear accelerometer features. The dataset was 'convolved' with the defined window size extracting nine different statistical values for each feature within a window: minimum, maximum, mean, RMS, sign, var, PFD, skewness, and kurtosis.
PAMAP2: this is a Physical Activity Monitoring dataset that contains data on 18 different physical activities (such as walking, cycling, playing soccer, etc.) performed by nine subjects wearing three inertial measurement units and a heart rate monitor. The dataset can be used for activity recognition and intensity estimation while developing and applying algorithms for data processing, segmentation, feature extraction, and classification. The goal is to recognize the type of activity based on sensor data.
The window with 512 sequential records was selected to represent the signal class.
The dataset contains a wide variety of different sensor data. A subset of accelerometer data and heart rate sensor was used for this experiment. Accelerometer features were 'convolved' with the defined window size with the extraction of statistical signal features based on the following research. This resulted in 108 features.
SisFall: This is a dataset of falls and activities of daily living (ADLs) acquired with a self-developed device composed of two accelerometer types and one gyroscope. It consists of 19 ADLs and 15 fall types performed by 23 young adults, 15 ADL types performed by 14 healthy and independent participants over 62 years old, and data from one participant of 60 years old that performed all ADLs and falls. The goal is to train the model to recognize a binary target – if a person falls or not.
The window with 135 sequential records was selected to represent the signal class.
The dataset was 'convolved' with the defined window size where the new training samples were comprised of all the values from the window in a single vector, including the nine statistical features of each window: minimum, maximum, mean, RMS, sign, var, PFD, skewness, kurtosis.
Tangible Benefits of the Automated TinyML Methodology
The use of the aforementioned automated and interoperable TinyML approach provides the community with the following benefits:
- Automated TinyML solutions significantly reduce IoT practitioners' time to market. In most domains, being among the first to introduce innovative products helps them to realize rapid market penetration, often resulting in increased revenues. For medical devices, for instance, rapid product delivery can save lives and improve quality of life.
- Automating the construction of TinyML models and eliminating the need to apply compression techniques to reach a specific model size makes it possible for non-data scientists (e.g., embedded engineers) to implement the entire range of tasks for building TinyML solutions. Furthermore, it saves a time-consuming hyperparameter search of a typical layer-based ANN, which is impractical to be hand-crafted.
- An automated pipeline allows specialists to refocus team resources on higher prioritized tasks instead of repetitive manual tasks prone to errors, such as, for instance, data acquisition, model optimization on the target, compression, validation on the field, etc.
- TinyML automation ensures significant optimization of ML model footprint and inference time due to optimal ANN structure and automated deployment. Moreover, it is possible to embed such models into incredibly small, resource-limited MCUs and intelligent sensors.
- The use of automated TinyML methodology opens up vast opportunities for the truly massive creation of IoT devices since the introduction of the AI component into the device has become more efficient.
Conclusions
TinyML technology enables even tiny devices that can contain complex AI logic, to run operations at low energy without sending data to the cloud or depending on the Internet connection, thus increasing data security and cutting down on costs. Automated TinyML methodology is a win-win scenario for IoT practitioners since it can greatly reduce the gaps inside the embedded developer community enabling all demographics to rapidly create and deploy TinyML solutions without long months of retraining or new skill acquisition.
To boost the development of the TinyML field, it is critical to create an optimal end-to-end pipeline that will allow such solutions to scale based on market demand and needs. The process illustrated in this article is defined to automate the design and deployment of ANNs efficiently. Automation is gaining momentum throughout the industry and will soon be the most dominant method within the market. The emergence of this methodology will create the foundation of innovation for various industry domains, from IoT to healthcare, agriculture, and environmental protection.
TinyML is rapidly evolving toward sensor AI computing, which means the ability to execute ANN within the sensor itself will soon be realized. Recently, STMicroelectronics announced the Intelligent Sensor Processing Unit (ISPU), capable of integrating inertial six-axis MEMs (Micro-Electro-Mechanical Systems) and DSP processor on the same silicon die.
An upcoming article will describe how to run TinyML operations into such a MEMS-based sensor.

Danilo Pau
(h-index 25, i10-index 61) graduated in 1992 Politecnico di Milano, Italy. One year before his graduation, he joined SGS-THOMSONS (now STMicroelectronics) as interns, where he worked on HDMAC hw design and then MPEG2 video memory reduction. Then, on video coding, transcoding, embedded graphics, and computer vision. Currently, his work focuses on developing solutions for tiny machine learning tools and applications.
Since 2019 Danilo is an IEEE Fellow; he served as Industry Ambassador coordinator for IEEE Region 8 South Europe, was vice-chairman of the “Intelligent Cyber-Physical Systems” Task Force within IEEE CIS, was IEEE R8 AfI member in charge of internship initiative, is a Member of the Machine Learning, Deep Learning and AI in the CE (MDA) Technical Stream Committee IEEE Consumer Electronics Society (CESoc) and was AE of IEEE TNNLS. He wrote the IEEE Milestone on Multiple Silicon Technologies on a chip, 1985 which was ratified by IEEE BoD in 2021 and IEEE Milestone on MPEG Multimedia Integrated Circuits, 1984-1993 which was ratified by IEEE BoD in 2022. He is serving as TPC member to TinyML EMEA forum and is the chair of the TinyML On Device Learning working group.
With over 81 patents, 137 publications, 113 MPEG authored documents and more than 61 invited talks/seminars at various worldwide Universities and Conferences, Danilo's favorite activity remains supervising undergraduate students, MSc engineers and PhD students cooperating with various universities in Italy, US, UK, France, and India.
 Andrey Korobitsyn is the founder and CEO at Neuton.AI, a San Jose-based provider of tiny machine learning solutions for edge devices. With over 20 years of experience in the IT business, Andrey oversees global development strategy and execution, which has enabled the company to grow from a startup to a steady market player. Andrey holds a Master's degree from the Moscow Engineering Physics Institute and a Ph.D. in Computer Science. He is also an alumnus of Stanford University Graduate School of Business and the American Institute of Business and Economics.
Andrey Korobitsyn is the founder and CEO at Neuton.AI, a San Jose-based provider of tiny machine learning solutions for edge devices. With over 20 years of experience in the IT business, Andrey oversees global development strategy and execution, which has enabled the company to grow from a startup to a steady market player. Andrey holds a Master's degree from the Moscow Engineering Physics Institute and a Ph.D. in Computer Science. He is also an alumnus of Stanford University Graduate School of Business and the American Institute of Business and Economics.
 Dmitry Proshin graduated from the Penza State Technical University in 1997 with a degree in Information Processing and later received a Ph.D. in technical sciences. After graduating, he worked in the software development field to automate production processes at NPF KRUG-SOFT LLC. At Bell Integrator, LLC, he became interested in developing intelligent algorithms in the banking sector. He has developed and implemented more than five unique subsystems and algorithms. In addition, he has been part of the Neuron neural network framework development team. Dmitry is the author of more than 150 works, including 25 articles, 5 monographs, and 6 manuals on topics such as mathematical methods of information processing, modeling, programming, software systems, SCADA, MES, and ERP systems, and educational methodology. He has received 4 state registration certificates for his developments and two patents.
Dmitry Proshin graduated from the Penza State Technical University in 1997 with a degree in Information Processing and later received a Ph.D. in technical sciences. After graduating, he worked in the software development field to automate production processes at NPF KRUG-SOFT LLC. At Bell Integrator, LLC, he became interested in developing intelligent algorithms in the banking sector. He has developed and implemented more than five unique subsystems and algorithms. In addition, he has been part of the Neuron neural network framework development team. Dmitry is the author of more than 150 works, including 25 articles, 5 monographs, and 6 manuals on topics such as mathematical methods of information processing, modeling, programming, software systems, SCADA, MES, and ERP systems, and educational methodology. He has received 4 state registration certificates for his developments and two patents.
 Danil Zherebtsov is a full-stack machine learning engineer with over 8 years of experience in the field. Before joining the Neuton team in 2019, he executed various end-to-end complex machine learning projects in multiple domains: telecom, networking, retail, manufacturing, marketing, fraud detection, oil and gas, engineering, and NLP. As a head of Machine Learning & Analytics at Neuton, Danil is working on the development of an automated TinyML platform facilitating sensor and audio data processing. Danil is an active contributor to the open-source community, with over 60,000 active users of tools featured in his repository. As an inspired writer, Danil publishes articles popularizing data science and introducing new methodologies for solving engineering tasks.
Danil Zherebtsov is a full-stack machine learning engineer with over 8 years of experience in the field. Before joining the Neuton team in 2019, he executed various end-to-end complex machine learning projects in multiple domains: telecom, networking, retail, manufacturing, marketing, fraud detection, oil and gas, engineering, and NLP. As a head of Machine Learning & Analytics at Neuton, Danil is working on the development of an automated TinyML platform facilitating sensor and audio data processing. Danil is an active contributor to the open-source community, with over 60,000 active users of tools featured in his repository. As an inspired writer, Danil publishes articles popularizing data science and introducing new methodologies for solving engineering tasks.