


Adaptive Deployments in IoT Applications: Necessity or Just Another Buzzword?
The nature of Internet of Things (IoT) applications have evolved from simple static sensing, monitoring and actuation applications to dynamic applications involving complex data analytics, large data storage, as well as stringent latency requirements. These applications include B2B scenarios like supply chain automation and optimization, predictive maintenance, connected and remote operations, as well as B2C scenarios like home automation and health coaching.
A research report from Technavio has predicted the IoT data analytics market to grow at 33% CAGR by $21.98B within 2022 [1]. This can be attributed to the prominent presence of cloud computing offering processing and storage resources to enable IoT analytics applications. However, the use of cloud computing affects the performance of applications which have a small perception-action time, with applications like speech recognition, augmented reality-based applications, e-health applications to name a few. The availability of processing devices with resources between constrained IoT devices and the cloud, composing the “edge computing” layer has played a key role in improving latency and Quality of Experience (QoE).
These edge computing devices are not nearly as rich as cloud computing in terms of resources and reliability. The topology comprising these devices is highly dynamic due to occurrences of device failure, joining and leaving of devices as well as connectivity issues. This results in a trade-off between stringent latency, reliability and hefty processing requirements. On one hand, we have applications which require historical data processing on the cloud with no immediate requirement of taking action, for e.g. sleep pattern monitoring on a subject. On the other hand, we would have fall/seizure detection on the same data which requires rapid detection and action. Additionally, reliability is critical to offer maximum uptime and to satisfy Quality of Service (QoS) requirements of applications. For example, for collision avoidance systems in vehicular networks, reliability is key as well as low latency.
Thus, statically deploying code on the edge or on the cloud restricts the efficient use of resources. Moreover, static deployments fail to handle the dynamic nature of IoT deployments involving mobility, topology changes, and device failures. Thus, in order to optimize the performance of IoT applications, we need adaptive deployments. If we look at an adaptive deployment system as a black box, it takes as an input the application to be deployed, requirements of the application and constraints of the processing resources to produce a deployment schema as an output, which meets the above requirements while satisfying the constraints. The key advantage that adaptive deployments bring to the table is the ability to sense changes like a device joining or a device running out of battery and reconfigure the deployment to optimize performance.
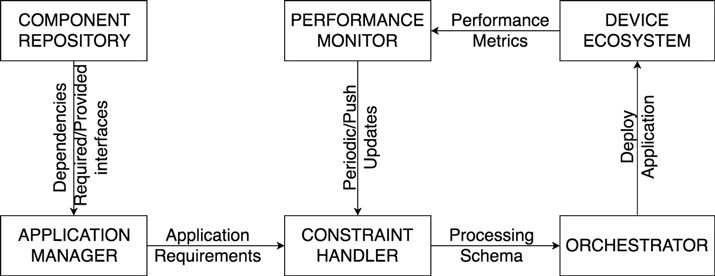
Figure 1: Modules of an adaptive deployment system.
Outline of an Adaptive Deployment System
An adaptive deployment system primarily consists of four modules namely, the performance monitor, the orchestrator, the application manager and the constraint handler as illustrated in figure 1. The application manager is responsible for composing an application from a repository of components which offer certain functionalities and are reusable in multiple applications. For example, in a data flow-oriented approach like Node-Red [1], a complex application is implemented by connecting various Node-Red nodes offering different functionalities. The components comprising each application have their own requirements in terms of memory and processing resources as well as software and hardware requirements like latency guarantees or presence of certain sensors/actuators on the device. The constraint handler takes into consideration the application components and their requirements and proposes a suitable processing schema which is then passed on to the orchestrator. The orchestrator is then responsible for building and deploying the components on the corresponding devices in accordance with the proposed schema. The performance monitor supervises the performance of the available resources. It ensures (i) the QoS requirements of the application are met and (ii) updates/changes in the system are passed to the constraint handler to reconfigure the system if necessary.
Challenges in Adaptive Deployments
- Uniform system description: system description plays a major role in defining the composition and requirements of an application as well as the definition of resource availability on the edge and cloud computing platforms. The system description language needs to be compatible with the orchestrator as well as the constraint handler. For example, developers of CHARIOT [2] implement their system in a smart parking use case offering fault tolerance and autonomous runtime reconfiguration based on their own domain-specific modeling language called CHARIOT-ML. On the other hand, developers of DIANE [3], a dynamic IoT application deployment framework, use MADCAT [4] methodology to define applications and components. Thus, having a uniform system description language will allow modules from different frameworks to be pluggable to each other and allow interoperability among frameworks.
- System performance monitoring: the key to adaptively reconfigure deployments in a multi-tier IoT system is to dynamically monitor the infrastructure to guarantee QoS requirements are met. Moreover, performance monitoring allows detection of faults and topology changes ensuring that the status of available resources remains up-to-date. The performance monitoring also facilitates the adaptation of the system according to changing application requirements. The challenges here lie in (i) prior knowledge of execution environments to monitor device performance, (ii) monitoring performances at different levels of the architecture, namely containers, virtual machines, and application require different tools and produce diverse metrics and (iii) collection and processing of the vast amount of data generated by the metrics and (iv) minimizing the overhead in monitoring performance.
- Diversity in device execution environments: the edge infrastructure is heterogeneous in terms of operating systems, underlying firmware/kernel, available resources, and supported application frameworks, among others. One way to handle this diversity is to deploy applications in the form of containers which are solely dependent on the underlying kernel of the device. However, for edge devices which lack the resources to support containerization, deploying application packages become quite challenging due to (i) lack of prior knowledge of supported/installed software (ii) limited functionality support from minimalized embedded OS and (iii) lack of prior knowledge of processor architecture (for example, ARM/x64/x86) for which application builds are different.
How Can Adaptive Deployments Be Beneficial?
Although the above challenges do exist, the dynamism and unpredictability of the edge layer in a multi-tier IoT ecosystem make adaptive deployments a perfect fit. Firstly, taking care of fault tolerance, the reliability of the entire system increases as well as the attrition of losses due to reduced downtime. Secondly, the reconfiguration of the deployment ensures inherent load balancing, thus improving device performance at the edge and improving energy efficiency. Thirdly, the ability to push deployments adaptively towards the edge also reduces cloud processing and storage costs, especially in pay-per-use models.
Conclusions
The research area of adaptive deployments and self-adaptive systems is a traditional one but like many other research topics, it has found new directions with the advent of IoT and edge computing. The increasing mashups of IoT with other domains like big data, machine learning, augmented reality, and blockchains, IoT applications are getting more and more complex by the day. These cross-disciplinary mashups contribute further to the uncertainty and dynamic nature of IoT deployments, calling for decentralized, reliable and scalable approaches. Adaptive deployments will become a necessity in this regard, to (i) enable dynamic, autonomous and distributed deployment of applications and (ii) optimize performance and improve resource utilization. Adaptive deployments come at a cost though, the overhead of monitoring performance, overcoming lack of interoperability among vendors and resource-constrained nature of edge devices. “Adaptive deployment” is not just a buzzword; as IoT research progresses further, these overheads can only get mitigated, transforming adaptive deployments into a necessary tool.
Acknowledgment
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 766139. This publication reflects only the author’s view and the REA is not responsible for any use that may be made of the information it contains.
References
- https://www.technavio.com/report/global-iot-analytics-market-analysis-share-2018
- https://nodered.org/
- https://github.com/visor-vu/chariot
- Vogler, Michael, et al. "DIANE-dynamic IoT application deployment." Mobile Services (MS), 2015 IEEE International Conference on. IEEE, 2015.
- Inzinger, Christian, et al. "MADCAT: A methodology for architecture and deployment of cloud application topologies." Service Oriented System Engineering (SOSE), 2014 IEEE 8th International Symposium on. IEEE, 2014.
 Koustabh Dolui is a Marie Skłodowska Curie Early Stage Researcher currently dividing his time pursuing a Ph.D. in Computer Science at the imec-DistriNet group of KU Leuven, Belgium and the Philips Personal Health, Netherlands. He is a part of the HEART Marie Curie ITN. Previously he has worked on the AGILE H2020 project at FBK-Create Net after graduating from Politecnico di Milano, Italy. He has presented his research work at multiple IEEE conferences and Linux Foundation events. He is interested in all things IoT and focuses on the scalability of processing in IoT architectures.
Koustabh Dolui is a Marie Skłodowska Curie Early Stage Researcher currently dividing his time pursuing a Ph.D. in Computer Science at the imec-DistriNet group of KU Leuven, Belgium and the Philips Personal Health, Netherlands. He is a part of the HEART Marie Curie ITN. Previously he has worked on the AGILE H2020 project at FBK-Create Net after graduating from Politecnico di Milano, Italy. He has presented his research work at multiple IEEE conferences and Linux Foundation events. He is interested in all things IoT and focuses on the scalability of processing in IoT architectures.
 Sam Michiels is an Industrial Research Manager within the imec-DistriNet group of the Department of Computer Science at KU Leuven. In 2003, he received his Ph.D. in Engineering/Computer Science from KU Leuven. Sam coordinates a team of 15 researchers and professors, all active in the domain of secure and networked embedded software. He is responsible for acquiring and coordinating multiple research projects and pro-actively endeavors to transfer academic know-how and expertise to/from industry. Sam has more than 20 years of experience of leading R&D and industrial projects.
Sam Michiels is an Industrial Research Manager within the imec-DistriNet group of the Department of Computer Science at KU Leuven. In 2003, he received his Ph.D. in Engineering/Computer Science from KU Leuven. Sam coordinates a team of 15 researchers and professors, all active in the domain of secure and networked embedded software. He is responsible for acquiring and coordinating multiple research projects and pro-actively endeavors to transfer academic know-how and expertise to/from industry. Sam has more than 20 years of experience of leading R&D and industrial projects.
 Hans Hallez obtained his Master degree in computer science (option ICT) at the Ghent University in 2003. He started his Ph.D. at the Medical Signal and Image Processing Research Group of the Department of Electronics and Information Systems (ELIS) at the Ghent University on biomedical signal analysis. He obtained his Ph.D. in 2008 in biomedical engineering. In 2013 Hans Hallez became part of the KU Leuven and started his work on middleware for adaptive edge computing and algorithm deployment in networked embedded systems within imec-DistriNet research group. He is currently (co-)author of about 90 publications.
Hans Hallez obtained his Master degree in computer science (option ICT) at the Ghent University in 2003. He started his Ph.D. at the Medical Signal and Image Processing Research Group of the Department of Electronics and Information Systems (ELIS) at the Ghent University on biomedical signal analysis. He obtained his Ph.D. in 2008 in biomedical engineering. In 2013 Hans Hallez became part of the KU Leuven and started his work on middleware for adaptive edge computing and algorithm deployment in networked embedded systems within imec-DistriNet research group. He is currently (co-)author of about 90 publications.
 Danny Hughes is a Professor with the Department of Computer Science of KU Leuven (Belgium), where he is a member of the imec-DistriNet (Distributed Systems and Computer Networks) research group and leads the Networked Embedded Software taskforce. He is also the Chief Technical Officer of Versasense NV, a KU Leuven spin-off company that provides end-to-end IoT solutions. Danny has a Ph.D. from Lancaster University (UK) and has since worked as a Visiting Scholar with the University of California at Berkeley (USA), a Visiting Scholar with the University of Sao Paulo (Brazil) and as a Lecturer with Xi'an Jiaotong-Liverpool University (China).
Danny Hughes is a Professor with the Department of Computer Science of KU Leuven (Belgium), where he is a member of the imec-DistriNet (Distributed Systems and Computer Networks) research group and leads the Networked Embedded Software taskforce. He is also the Chief Technical Officer of Versasense NV, a KU Leuven spin-off company that provides end-to-end IoT solutions. Danny has a Ph.D. from Lancaster University (UK) and has since worked as a Visiting Scholar with the University of California at Berkeley (USA), a Visiting Scholar with the University of Sao Paulo (Brazil) and as a Lecturer with Xi'an Jiaotong-Liverpool University (China).
Sign Up for IoT Technical Community Updates
Calendar of Events
IEEE 8th World Forum on Internet of Things (WF-IoT) 2022
26 October-11 November 2022
Call for Papers
IEEE Internet of Things Journal
Special issue on Towards Intelligence for Space-Air-Ground Integrated Internet of Things
Submission Deadline: 1 November 2022
Special issue on Smart Blockchain for IoT Trust, Security and Privacy
Submission Deadline: 15 November 2022
Past Issues
September 2022
July 2022
March 2022
January 2022
November 2021
September 2021
July 2021
May 2021
March 2021
January 2021
November 2020
July 2020
May 2020
March 2020
January 2020
November 2019
September 2019
July 2019
May 2019
March 2019
January 2019
November 2018
September 2018
July 2018
May 2018
March 2018
January 2018
November 2017
September 2017
July 2017
May 2017
March 2017
January 2017
November 2016
September 2016
July 2016
May 2016
March 2016
January 2016
November 2015
September 2015
July 2015
May 2015
March 2015
January 2015
November 2014
September 2014
Comments
2018-11-17 @ 6:41 AM by Milis, George
Dear authors,